 LINGCORE SCI
LINGCORE SCI
Mastering Heterogeneity in Meta-Analysis: Subgroup Analysis and Meta-Regression Strategies
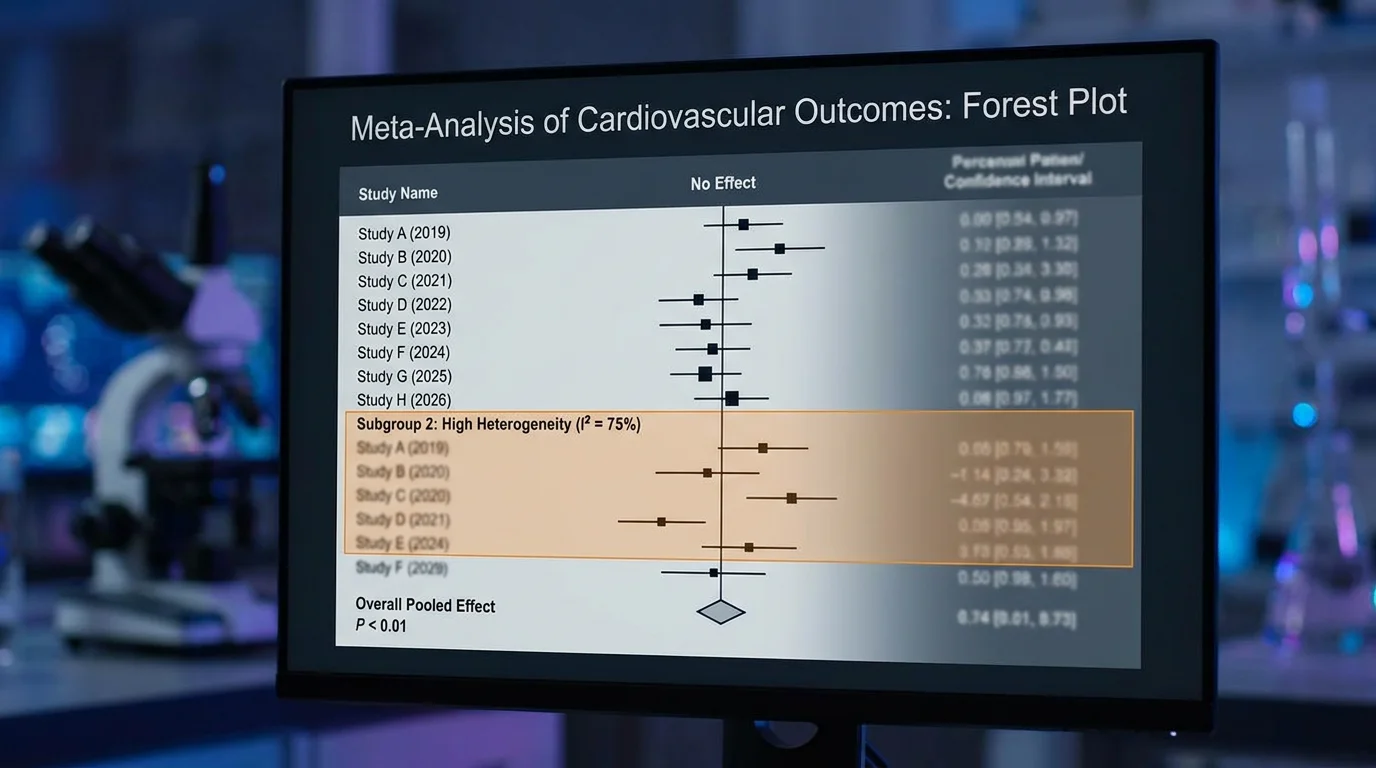
In the domain of evidence-based medicine, the meta-analysis is often regarded as the peak of the evidence hierarchy. By pooling data from multiple studies, researchers aim to achieve a more precise estimate of an intervention's effect. However, a common obstacle that arises in this process is heterogeneity—the variation in study outcomes beyond what would be expected by chance. While a low level of heterogeneity is ideal for a clean synthesis, high heterogeneity is not a failure of the analysis; rather, it is a clinical and methodological opportunity to understand why treatment effects vary across different settings and populations.
For medical researchers, simply reporting an I-squared (I²) value is no longer sufficient for high-impact SCI publication. Contemporary standards require a rigorous exploration of the sources of variation through subgroup analysis and meta-regression. This article provides a comprehensive roadmap for identifying, quantifying, and explaining heterogeneity to ensure your meta-analysis meets the most stringent peer-review requirements in 2026.
1. The Inevitability of Heterogeneity
Heterogeneity is inherent in medical research. No two studies are identical. They differ in their patient populations (clinical heterogeneity), their study designs (methodological heterogeneity), and the quality of their execution (statistical heterogeneity). The primary goal of a meta-analyst is not to ignore this variation, but to determine whether it is combinable. If studies are so different that pooling them is "comparing apples and oranges," a quantitative synthesis may be inappropriate, and a qualitative systematic review should be preferred.
The first step in any meta-analysis is to visualize this variation. A Forest Plot is the standard tool for this, allowing researchers to see at a glance how study effects and their confidence intervals overlap. If the confidence intervals do not overlap, or if studies lie on opposite sides of the line of no effect, heterogeneity is almost certainly present.
2. Quantifying the Mess: Beyond Cochrane's Q and I²
While the Cochrane's Q test provides a p-value for the presence of heterogeneity, it is notoriously low-powered when study numbers are small and over-sensitive when they are large. Therefore, the I² statistic has become the preferred metric for quantifying the magnitude of variation.
- I² < 25%: Low heterogeneity (variation is mostly due to sampling error).
- I² 25% - 75%: Moderate heterogeneity (requires further investigation).
- I² > 75%: High heterogeneity (pooling must be justified, and sources must be explored).
However, I² only tells you how much variation exists, not what causes it. To understand the "why," we must turn to more advanced analytical techniques.

3. Source Identification: The Triad of Variation
Before running a single subgroup test, researchers must categorize potential sources of heterogeneity into a three-part framework:
- Clinical Heterogeneity: Differences in participant characteristics (age, disease severity, comorbidities) or the intervention itself (dosage, duration, co-interventions).
- Methodological Heterogeneity: Differences in study design (RCT vs. observational), risk of bias, follow-up duration, or the definition of outcomes.
- Statistical Heterogeneity: The observable manifestation of the first two categories in the study results.
A rigorous meta-analysis pre-specifies these potential sources in the protocol (e.g., via PROSPERO) to avoid the risk of "data dredging" later in the analysis.
4. Subgroup Analysis: Principles and Pitfalls
Subgroup analysis involves splitting the data into subsets based on a specific characteristic (e.g., studies with a follow-up of >12 months vs. <12 months). This is the most common method for exploring heterogeneity when the covariate is categorical.
The Golden Rules of Subgroup Analysis:
- Pre-specification: Hypotheses regarding subgroup differences must be defined before the analysis. Post-hoc subgrouping is highly susceptible to spurious findings.
- Limited Comparisons: The more subgroups you test, the higher the risk of a Type I error (finding a difference where none exists).
- Interaction Tests: Do not simply compare the p-values of two subgroups. You must use a formal test of interaction (e.g., the Q-test for subgroup differences) to determine if the difference between groups is statistically significant.
5. Meta-Regression: Explaining the Variance
When the source of heterogeneity is a continuous variable (e.g., mean age of participants, baseline disease score), meta-regression is the tool of choice. Think of it as a linear regression where the "units" are studies rather than individuals.
In a meta-regression, the dependent variable is the treatment effect (e.g., Log Odds Ratio), and the independent variables are study-level covariates. A bubble plot is the standard visualization here, showing how the effect size changes as the covariate increases.
Key Warning: Meta-regression is susceptible to ecological bias. A relationship observed at the study level (e.g., studies with older patients show less effect) does not necessarily hold true at the individual patient level (e.g., an individual older patient will have less effect). To establish patient-level relationships, an Individual Participant Data (IPD) meta-analysis is required.
6. Sensitivity Analysis: Testing Robustness
A sensitivity analysis is not used to explain heterogeneity, but to test whether the overall conclusion is robust to changes in the analysis. This typically involves:
- Excluding studies with a high risk of bias.
- Comparing the results of Fixed-Effect vs. Random-Effects models.
- Excluding "outlier" studies that have an extreme influence on the pooled estimate.
If the conclusion remains consistent across these variations, you can have high confidence in your results. If it changes, the heterogeneity must be discussed with extreme caution.
7. Reporting Guidelines: PRISMA 2020 Compliance
In 2026, adherence to the PRISMA 2020 statement is non-negotiable for high-impact SCI journals. Regarding heterogeneity, you must:
- Explicitly state the methods used to assess heterogeneity (Section 10.b).
- Report the results of all subgroup analyses and meta-regressions (Section 13.e).
- Discuss how the heterogeneity impacts the certainty of the evidence (e.g., using the GRADE approach).
Elevate Your Research with Lingcore SCI Tools
Mastering complex statistical synthesis is a journey toward academic excellence. Leverage our AI-powered toolset to ensure your meta-analysis stands out to SCI editors:
- Paper Analyzer: Perform a deep-dive audit of your heterogeneity assessment and risk of bias reporting.
- Review Builder: Generate structured meta-analysis drafts with automated citation mapping and PICO alignment.
- Journal Matcher: Find the high-impact SCI journal that best fits your systematic review's scope and quality.
Conclusion
Heterogeneity is the pulse of a meta-analysis. It is the data's way of telling us that the "average" effect is not the whole story. By moving beyond simple I² reporting and employing rigorous subgroup and meta-regression strategies, you provide a much more nuanced and clinically relevant picture of the evidence. In the competitive world of medical publication, the ability to turn "statistical noise" into "scientific insight" is what separates a standard paper from a high-impact contribution.