 LINGCORE SCI
LINGCORE SCI
Causal Inference in Observational Medical Research: G-Methods and Propensity Scores

In the hierarchy of medical evidence, the randomized controlled trial (RCT) remains the gold standard for establishing causal relationships. By randomly assigning participants to treatment or control arms, RCTs effectively eliminate both known and unknown confounding, allowing for an unbiased estimation of the average treatment effect. However, RCTs are not always feasible, ethical, or timely. For many critical clinical questions, researchers must rely on observational data derived from electronic health records, insurance claims, or disease registries.
The primary challenge of observational research is confounding—the distortion of an association because of factors that influence both treatment selection and the clinical outcome. In 2026, simply reporting multivariable-adjusted regression models is no longer sufficient to secure publication in high-impact SCI journals. Top-tier editors demand the application of formal causal inference frameworks, specifically propensity scores and G-methods, to emulate target trials and draw reliable causal conclusions. This article provides a comprehensive guide to utilizing these advanced statistical methodologies in your observational clinical research.
1. Directed Acyclic Graphs (DAGs): Visualizing Causal Logic
Before performing any statistical adjustment, researchers must define their causal hypotheses. The standard tool for this is the Directed Acyclic Graph (DAG). A DAG is a visual representation of the assumed causal relationships among the exposure, the outcome, and covariates.
In a DAG, variables are represented as "nodes," and assumed causal directions are drawn as "arrows" (directed edges). Crucially, a DAG must contain no loops (acyclic), meaning an arrow cannot lead back to a preceding node. Using a DAG allows researchers to identify which variables are true confounders (requiring adjustment), which are mediators (must not be adjusted), and which are colliders (where adjustment would introduce selection bias, known as collider-stratification bias). Software tools like **DAGitty** are now mandatory accompaniments to high-level clinical manuscripts to justify covariate selection.
2. Propensity Score Methods: Emulating Randomization
Introduced by Rosenbaum and Rubin, the Propensity Score (PS) is defined as the probability of a patient receiving a treatment, conditional on their observed baseline covariates. By balancing the distribution of covariates between treatment groups, PS methods aim to emulate the baseline balance achieved in randomized trials.
There are four primary ways to utilize propensity scores in clinical analyses:
- Propensity Score Matching (PSM): Pairing treated patients with untreated patients who have identical or near-identical propensity scores. This is highly intuitive but often discards a large portion of the sample if treatment groups are highly unbalanced.
- Inverse Probability of Treatment Weighting (IPTW): Assigning weights to each patient based on the inverse of their probability of receiving the treatment they actually received. This creates a pseudo-population where the exposure is independent of the baseline covariates, utilizing the entire sample.
- Propensity Score Stratification: Dividing the sample into quintiles or deciles based on propensity scores, allowing for comparisons within relatively homogeneous subgroups.
- Propensity Score Adjustment: Including the propensity score as a single continuous covariate in a regression model. This is the least robust method and is generally discouraged compared to IPTW or PSM.
A critical step in PS analysis is verifying the covariate balance. Researchers must report the **Standardized Mean Difference (SMD)** for each covariate before and after adjustment; an SMD of less than 0.1 indicates an acceptable balance.
3. The Limitations of Propensity Scores in Longitudinal Research
While propensity scores are highly effective for static, point-in-time exposures, they fail in longitudinal studies where exposures and confounders change over time. In clinical practice, treatments are modified, and patients are monitored sequentially. This introduces a phenomenon known as time-varying confounding.
When a time-varying covariate acts simultaneously as a confounder and a mediator (lying on the causal pathway between past treatment and the outcome, while also being influenced by past treatment), traditional propensity score or regression adjustments fail. Adjusting for the covariate blocks the causal effect through the mediator, while failing to adjust for it leaves the confounding unaddressed. To resolve this paradox, researchers must turn to **G-methods**.
4. G-Methods: The Frontier of Causal Inference
Developed by James Robins, **G-methods** (generalized methods) are a class of advanced statistical techniques designed to estimate causal effects in the presence of time-varying confounding. The three primary G-methods are:
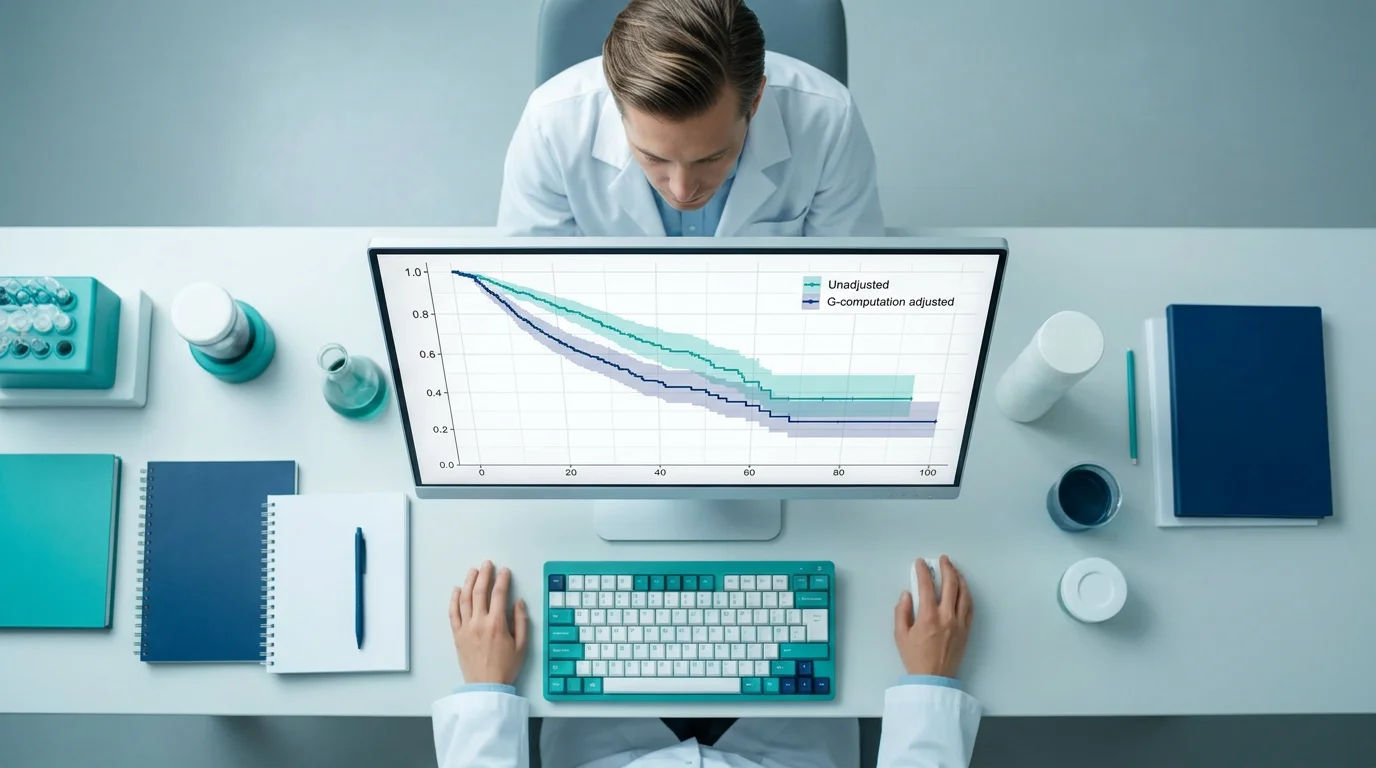
- G-Formula (G-Computation): A standardization method that simulates the counterfactual outcomes of the entire cohort under different treatment scenarios, averaging the predicted outcomes over the distribution of the time-varying confounders.
- Inverse Probability Weighted (IPW) Marginal Structural Models (MSMs): Extends IPTW to the time-varying setting. It applies time-dependent weights to account for both baseline and time-varying confounding, effectively cutting the links between past confounders and future treatment decisions in the pseudo-population.
- G-Estimation of Structural Nested Models: Primarily used to study the joint effects of multiple treatments or when the outcome of interest is a continuous marker or survival time.
Among these, **Marginal Structural Models (MSMs)** are the most widely applied in contemporary medical research. By adjusting for time-varying confounding without blocking mediation, MSMs have successfully redefined therapeutic efficacy in complex, longitudinal observational cohorts, such as HIV treatment and cardiovascular registries.
5. Double Robust Estimation: Minimizing Model Misspecification
To further protect against bias, clinical scientists utilize Double Robust (DR) Estimation (such as Targeted Maximum Likelihood Estimation, TMLE). A double robust estimator combines a model for the exposure (the propensity score model) and a model for the outcome (the regression model).
The remarkable feature of double robust estimation is that the treatment effect estimate remains unbiased if **either** the exposure model OR the outcome model is correctly specified. This "two chances to be right" property provides a powerful safeguard against model misspecification, significantly increasing the credibility of observational results submitted to premier SCI journals.
6. Reporting Standards and Target Trial Emulation
To ensure transparency, researchers must align their reporting with the **STROBE** statement and the emerging framework of **Target Trial Emulation**. In target trial emulation, researchers explicitly draft the protocol of the hypothetical randomized trial they *wish* they could run, and then detail how their observational data and causal inference methods are used to replicate that trial's eligibility criteria, treatment strategies, assignment procedures, and outcome definitions.
Elevate Your Research with Lingcore SCI Tools
Emulating target trials and executing advanced causal inference requires strict methodological precision. Lingcore SCI provides specialized AI-driven tools to ensure your research meets the highest publication standards:
- Paper Analyzer: Audit your observational manuscript against STROBE guidelines and target trial emulation checklists.
- Review Builder: Generate structured literature reviews on advanced G-methods with verified citations.
- Journal Matcher: Match your real-world evidence study to the high-impact SCI journals that prioritize causal inference rigor.
Conclusion
Observational research is entering a new era of scientific rigor. By moving beyond traditional regression and embracing Directed Acyclic Graphs, propensity scores, and G-methods, medical researchers can generate high-quality, causal evidence from real-world data. While these techniques require rigorous statistical planning and operational precision, they bridge the gap between observation and causation. In the competitive landscape of medical publishing, the ability to control time-varying confounding and emulate target trials is what transforms simple database queries into groundbreaking, practice-changing scientific contributions.